Intelligenza Artificiale, Dati Aziendali e il Nuovo Paesaggio Normativo Europeo
La diffusione rapidissima di tecnologie basate sull’intelligenza artificiale generativa (Generative AI), come programmi noti e soluzioni open-source (llama3, llamaindex, Qdrant) accessibili tramite piattaforme cloud, ha trasformato radicalmente l’ambiente aziendale. Questo scenario offre nuove e significative opportunità per l’analisi e l’utilizzo strategico dei dati aziendali.
Le organizzazioni possono ora sviluppare rapidamente soluzioni personalizzate, come chatbot per l’assistenza clienti o per il supporto al personale tecnico. In settori ad alta intensità tecnologica, l’utilizzo dell’intelligenza artificiale può migliorare le prestazioni dei sistemi energetici e, allo stesso tempo, aiutare gli addetti ai lavori a progettare e perfezionare gli impianti.
draw an owl is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
In questo contesto, il machine learning e il deep learning possono risolvere i problemi di utilizzo degli impianti energetici, rilevando anomalie e ottimizzando la produzione e i consumi energetici (Olabi et al., 2023).
Nonostante la relativa facilità di implementazione di tali soluzioni, è fondamentale considerare gli aspetti legati alla privacy e all’utilizzo dei dati, sia quelli già presenti nei database aziendali sia quelli che gli utenti forniranno durante l’utilizzo delle applicazioni.
Il Regolamento generale sulla protezione dei dati (GDPR, 2016), in vigore dal 2018, e l’AI Act, approvato dal Parlamento Europeo nel 2024,, forniscono la cornice normativa essenziale su cui basare il design di queste applicazioni. La gestione dell’intelligenza artificiale e dei big data, sebbene apporti innumerevoli vantaggi, necessita di un’attenta conoscenza dei concetti principali evidenziati in entrambi i regolamenti. La sfida manageriale consiste nell’adottare un approccio “compliant by design” (AI Compliant by design, Naaia, 2024) per armonizzare lo sviluppo tecnologico con l’obbligo di tutelare la privacy e i dati sensibili, cercando di armonizzare il più possibile le norme dell’AI Act e del GDPR (Falletta et al., 2024).

artificial intelligence, GDPR and AI Act
Le aziende che investono nella trasparenza e in un uso etico dell’intelligenza artificiale possono sviluppare sistemi sostenibili ed ottenere un vantaggio competitivo (Patil et al. 2024).
Un punto di intersezione cruciale tra le due normative è l’enfasi sulla trasparenza e sulla explainability (interpretabilità) dei sistemi automatizzati.
Il GDPR include al suo interno la definizione di “right to explanation” (diritto di spiegazione), e l’AI Act, che pone molta enfasi sulla trasparenza e sulla “explainability”, può andarsi ad integrare con le norme già previste dal GDPR (L. Metikoš e J. Ausloos, 2024). L’AI Act mira a favorire la trasparenza, stabilendo che i sistemi di intelligenza artificiale e i loro risultati debbano poter essere compresi anche dai non addetti ai lavori (R. Schwartmann et al., 2024).
L’articolo 22 del GDPR, che regola il trattamento dei dati nei processi decisionali automatizzati, si integra con l’AI Act nelle sezioni in cui questo regola i sistemi AI che prevedono profilazione o l’utilizzo di dati sensibili, quindi in sistemi ad alto rischio (Falletta et al., 2024). Queste discussioni possono delineare un nuovo “diritto di interpretabilità” all’interno della legislazione europea (Gallese, 2023). Inoltre, la Valutazione d’Impatto sulla Protezione dei Dati (DPIA) del GDPR e la Valutazione d’Impatto sui Diritti Fondamentali (FRIA) dell’AI Act presentano punti di unione significativi (T. Rintamäki et al., 2024), entrambe finalizzate a mitigare i rischi prima che un’applicazione ad alto rischio venga implementata.
Per affrontare le complessità normative e garantire flessibilità operativa, l’adozione di una strategia dual-track è spesso consigliata, sviluppando sistemi sia su piattaforme proprietarie (come i GPTs) sia su soluzioni open-source ospitate su cloud. L’approccio dual-track permette inoltre di effettuare una vera e propria analisi comparativa (A/B testing) delle prestazioni delle due piattaforme. La trasparenza è un elemento che caratterizza sia l’AI Act che il GDPR (AI Act e Gdpr, Agenda Digitale, 2024) ed è essenziale per preservare la fiducia dei soggetti interessati (Ledro et al.,2023), specialmente nei settori come il Customer Relationship Management (CRM) in cui i chatbot sono impiegati (Khneyzer et al.,2024).
A livello manageriale, l’implementazione richiede una rigorosa governance dei dati, e l’utilizzo dei dati personali degli utenti va opportunamente anonimizzato e gestito con tecniche di crittografia. La formazione del personale è cruciale, poiché studi hanno evidenziato come l’integrazione di chatbot basati su IA nei sistemi di marketing abbia creato significativi miglioramenti nell’ottimizzazione delle operazioni (Kedi et al.,2024). Tuttavia, dato che i modelli di linguaggio, basati sulla probabilità, possono incorrere in allucinazioni e generare risposte scorrette o fuorvianti, è indispensabile che i sistemi operino sotto costante supervisione umana.
Il personale deve essere formato per utilizzare i nuovi strumenti in maniera consapevole. L’articolo 14 dell’AI Act, ad esempio, prevede che una persona fisica supervisioni costantemente i sistemi di intelligenza artificiale (Reinforcement Learning by Human Factor/Supervision), data la loro natura mutevole. In tal senso, è opportuno poter risalire rapidamente ai dati che hanno generato una risposta e comprendere l’output (Falletta et al, 2024).
Modelli Open-Source, Database Vettoriali e Generazione Aumentata (RAG): breve spiegazione tecnica
La menzione di soluzioni open-source come llama3, llamaindex e Qdrant evidenzia una chiara tendenza verso l’adozione di piattaforme flessibili e personalizzabili, in contrasto con le soluzioni proprietarie (come i GPT di OpenAI). Questa strada è spesso preferita dalle aziende che mirano a mantenere un controllo più stretto sui propri dati e a garantire la conformità normativa.
I Modelli di Linguaggio Open-Source: Llama, Mixtral e DeepSeek
Il panorama dei Large Language Models (LLM) accessibili gratuitamente e con licenze permissive (open-weight/open-source) è dominato da giganti come Meta, con la sua famiglia Llama, e da startup innovative che stanno spingendo i limiti dell’efficienza e delle prestazioni:
Mixtral (Mistral AI): Questa startup francese ha guadagnato l’attenzione globale rilasciando modelli estremamente potenti con licenza Apache 2.0, che ne consente l’uso commerciale libero. Il modello di punta, Mixtral 8x7B, utilizza un’architettura avanzata nota come Mixture of Experts (MoE). In pratica, pur avendo un elevato numero totale di parametri (46.7 miliardi), per ogni token di input ne attiva solo una frazione (12.9 miliardi). Questo approccio permette di ottenere prestazioni paragonabili o superiori a modelli chiusi come GPT-3.5, con una velocità di inferenza (generazione della risposta) fino a sei volte superiore e a costi notevolmente inferiori. Questa efficienza è cruciale per l’implementazione locale (on-premise), che è strategicamente importante per la sicurezza dei dati e la conformità al GDPR, consentendo l’esecuzione su hardware accessibile.
DeepSeek: Proveniente dalla Cina, il laboratorio DeepSeek ha rilasciato LLM (come DeepSeek-V3 o DeepSeek-R1) che sfidano i leader occidentali in termini di performance, in particolare nel ragionamento matematico e nella generazione di codice. DeepSeek si è distinto per aver raggiunto prestazioni elevate con costi di addestramento significativamente più bassi, anch’esso implementando spesso l’architettura MoE.
Similmente a Mixtral, i modelli DeepSeek supportano l’uso gratuito e l’esecuzione su hardware consumer, rendendoli un’alternativa economicamente vantaggiosa per le aziende che desiderano implementare l’IA senza dipendere da grandi infrastrutture cloud proprietarie.
Vector Databases e RAG (Generazione Aumentata da Recupero)
L’utilizzo di modelli di linguaggio open-source per compiti aziendali specifici è quasi sempre associato all’implementazione della tecnica Retrieval-Augmented Generation (RAG) [6]. Questa metodologia è essenziale per istruire un modello pre-addestrato (come Llama 3 o Mixtral) con la base di conoscenza specifica di un’azienda (Knowledge Base), senza dover effettuare un costoso e complesso ciclo di fine-tuning.
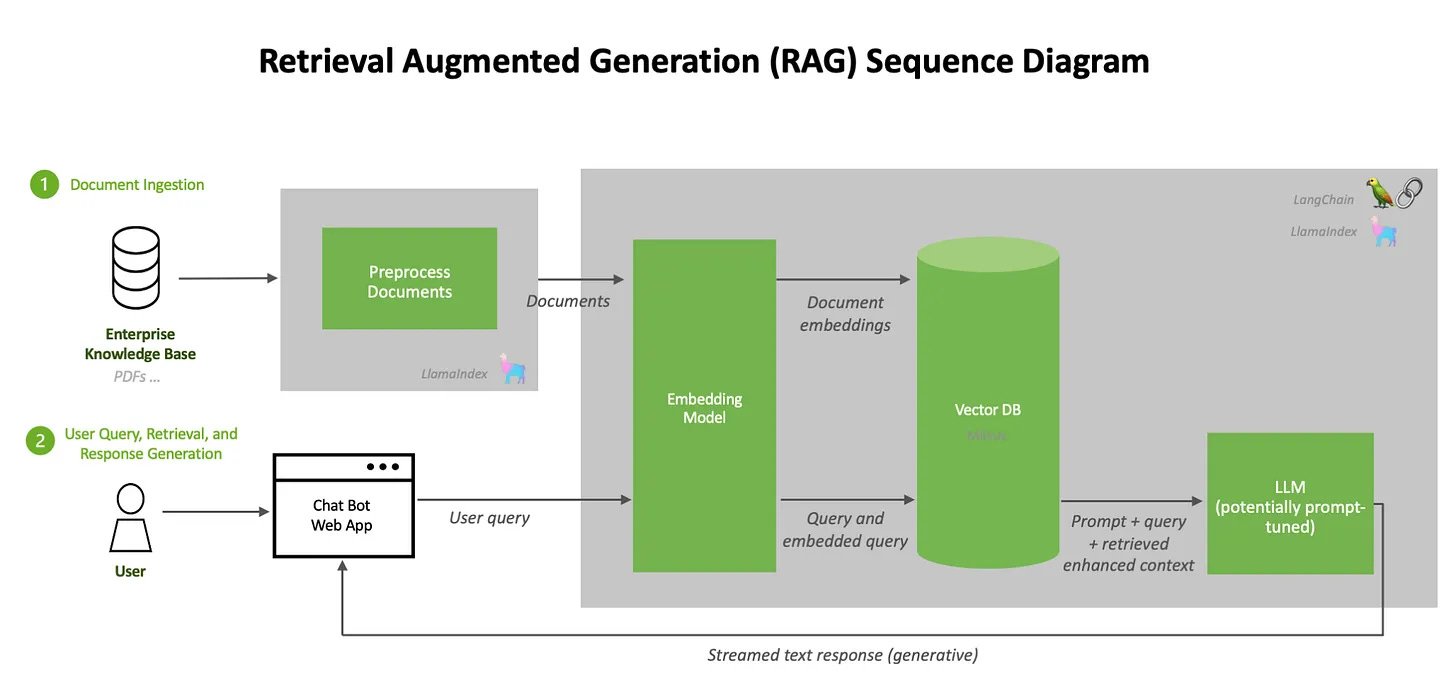
Panoramica dei componenti di una pipeline RAG: flussi di acquisizione e query. Source: https://developer.nvidia.com/blog/rag-101-demystifying-retrieval-augmented-generation-pipelines/
Il processo RAG si articola in tre componenti chiave:
Knowledge Base ed Embeddings: I dati aziendali (documenti, manuali, contratti) vengono convertiti in vettori numerici, noti come embeddings, che rappresentano il significato semantico del contenuto.
Vector Database (es. Qdrant): Questi embeddings vengono archiviati in un database vettoriale dedicato (come Qdrant), che è ottimizzato per il recupero semantico rapido [9]. Quando l’utente inserisce una query, anche questa viene convertita in un vettore. Il database vettoriale cerca e recupera i documenti aziendali (i “chunk” di testo) il cui vettore è più vicino semanticamente a quello della query.
Generator (LLM): Il modello di linguaggio (ad esempio Llama 3) riceve la query originale più il testo pertinente recuperato dal database vettoriale. In questo modo, il modello può generare una risposta accurata e basata sui fatti aziendali, riducendo significativamente il rischio di “allucinazioni” (risposte generate, ma errate).
L’approccio RAG, in combinazione con i modelli open-source, offre un equilibrio tra prestazioni, personalizzazione, economicità e, soprattutto, un maggiore controllo sulla fonte dei dati utilizzati, facilitando l’adozione di un approccio “compliant by design”.
📢 Disclaimer
Si precisa che la menzione di specifici strumenti e modelli di Intelligenza Artificiale (come llama3, Mixtral, DeepSeek, Qdrant, GPTs, etc.) è avvenuta a solo scopo didattico, tecnico ed esemplificativo. Non sussiste alcuna affiliazione commerciale, partnership o endorsement economico tra l’autore e le aziende o i progetti open-source proprietari di tali servizi.
References
-
AI Act e Gdpr: come si integrano le norme sulla protezione dei dati, Agenda Digitale. Available at: https://www.agendadigitale.eu/sicurezza/privacy/ai-act-e-gdpr-come-si-integrano-le-norme-sulla-protezione-dei-dati/
-
AI Compliant by design, Naaia. Available at: https://naaia.ai/navigating-ai-design-with-a-new-compass-compliant-by-design-ai-systems/,
-
P. Falletta and A. Marsano, «Intelligenza artificiale e protezione dei dati personali: il rapporto tra Regolamento europeo sull’intelligenza artificiale e GDPR», Rivista italiana di informatica e diritto, vol. 6, fasc. 1, Art. fasc. 1, doi: 10.32091/RIID0155.,
-
C. Gallese, «The AI Act Proposal: a New Right to Technical Interpretability?», Social Science Research Network, Rochester, NY: 4398206. doi: 10.2139/ssrn.4398206.,
-
C. G. Granmar, «AI-Based Decision-Making and the Human Oversight Requirement Under the AI Act», in YSEC Yearbook of Socio-Economic Constitutions 2023: Law and the Governance of Artificial Intelligence, E. Gill-Pedro and A. Moberg, Eds., Cham: Springer Nature Switzerland, 2024, pp. 181-209. doi: 10.1007/16495 2024 68.,
-
W. E. Kedi, C. Ejimuda, C. Idemudia, and T. I. Ijomah, «AI Chatbot integration in SME marketing platforms: Improving customer interaction and service efficiency», International Journal of Management & Entrepreneurship Research, vol. 6, fasc. 7, Art. fasc. 7, doi: 10.51594/ijmer.v6i7.1327.,
-
C. Khneyzer, Z. Boustany, and J. Dagher, «AI-Driven Chatbots in CRM: Economic and Managerial Implications across Industries», Administrative Sciences, vol. 14, fasc. 8, Art. fasc. 8, doi: 10.3390/admsci14080182.,
-
Cristina Ledro, Anna Nosella, Ilaria Dalla Pozza, «Integration of AI in CRM: Challenges and guidelines - ScienceDirect», December 2023, Available at: https://www.sciencedirect.com/science/article/pii/S2199853123002536,
-
L. Metikoš and J. Ausloos, «The Right to an Explanation in Practice: Insights from Case Law for the GDPR and the AI Act», OSF. doi: 10.31219/osf.io/ezgxf.,
-
A. G. Olabi, M. A. Abdelkareem, and H. Jouhara, “Energy digitalization: Main categories, applications, merits, and barriers,” Energy, vol. 271, p. 126899, doi: 10.1016/j.energy.2023.126899.,
-
T. Rintamäki, D. Golpayegani, E. Celeste, D. Lewis, and H. J. Pandit, «High-Risk Categorisations in GDPR vs AI Act: Overlaps and Implications», OSF. doi: 10.31219/osf.io/6qhzj.,
-
R. Schwartmann, T. Keber, K. Zenner, and S. Kurth, «Data Protection Aspects of the Use of Artificial Intelligence - Initial overview of the intersection between GDPR and AI Act», Computer Law Review International, vol. 25, fasc. 5, pp. 145-150, doi: 10.9785/cri-2024-250503.
Riferimenti per il paragrafoModelli Open-Source, Database Vettoriali e Generazione Aumentata (RAG)
-
Agenda Digitale, “AI per i cittadini, a che punto siamo in Ue: il caso Mistral” https://www.agendadigitale.eu/cultura-digitale/ai-per-i-cittadini-a-che-punto-siamo-in-ue-il-caso-mistral/.
-
Mistral AI Team, “Mixtral of experts,” Mistral AI Blog, 11 dicembre 2023. Available at: https://mistral.ai/news/mixtral-of-experts.
-
«Introducing Meta Llama 3: The most capable openly available LLM to date», Meta AI. Disponibile su: https://ai.meta.com/blog/meta-llama-3/
-
Agenda Digitale, “Ai gen per il project manager: l’esperimento con Deepseek e Mistral” https://www.agendadigitale.eu/procurement/ai-gen-per-il-project-manager-lesperimento-con-deepseek-e-mistral/.
-
IBM, “DeepSeek: comprendere l’hype,” 24 marzo 2025. Available at: https://www.ibm.com/it-it/think/topics/deepseek.
-
P. B. Consulting, “DeepSeek la guida completa. Perchè non è un problema di privacy,” 2 febbraio 2025.
-
Lewis, P. et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” ArXiv abs/2005.11401, 2020.
-
Amazon Web Services (AWS), “What is RAG? - Retrieval-Augmented Generation AI Explained.” Available at: https://aws.amazon.com/what-is/retrieval-augmented-generation/.
-
NVIDIA Blog, “What Is Retrieval-Augmented Generation aka RAG,” 31 gennaio 2025. Available at: https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/.
-
K2view, “LLM vector database: Why it’s not enough for RAG.” https://www.k2view.com/blog/llm-vector-database/
-
lakeFS, “Best 17 Vector Databases for 2025 [Top Picks],” 20 ottobre 2025. Available at: https://lakefs.io/blog/best-vector-databases/.
Originally posted on Draw an Owl 🦉. Subscribe & Sustain on Substack!